not logged in | [Login]
The message API is designed to exchange messages between network and worker threads.
The v3 design is just a REQUEST structure, and a FIFO, along with
mutexes for thread safety. This design works, but has issues. For
one, mutex contention is a problem. Two, memory is often allocated in
one thread and freed in another. The API is simple, but not
sophisticated.
The goals for the v4 message API are:
The design of the message API in v4 relies on three components.
First, there is a thread-safe queue of messages. The queue itself does not contain the messages, but instead contains pointers to the messages. This choice means that the queue is small, and easily manageable. It also means that writes to the queue are atomic.
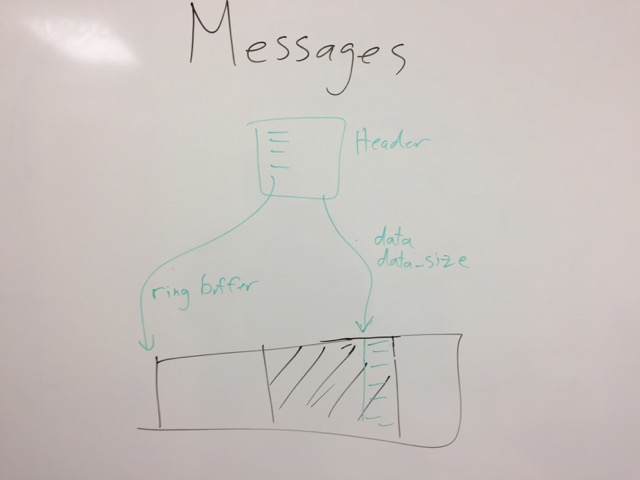
Second, there is a slab allocator message headers. The message headers are fixed size, and do not need to be allocated / freed for every message.
Third, there is a ring buffer for packet data. This buffer is large (64K to 1M+), and contains the raw packet data.
An important part of the message implmentation is that there are multiple instances of the message API (i.e. the three items noted above). For example, a network thread may have one instance for each socket that it's reading from, and a worker thread may have one for each network thread it's writing packets to.
The reason for multiple instances is not just thread-safety, but management. One of the most common problems in asynchronous systems is data ownership. Owning data is cheap, exchanging ownership of data is expensive.
In this model, the system that creates messages is the system that owns the message. The message target can (temporily) access the message, but it does not own the message.
The messages are also ephemeral, and short lived. If the data is needed for any length of time, it must be copied out of the message subsystem to somewhere else.
The queue of messages is a simple FIFO set of pointers. Where possible, this is done via a lockless queue. Otherwise, mutexes are used. We may also want a ring buffer for the queue, as it's just pointers. Then, CAS for updates...
Queues are owned by the recipient of the messages. i.e. multiple originators send messages to one queue. Each recipient (worker thread, network socket, etc.) has it's own queue.
Messages are placed onto the queue by the originator, and the destination is signalled that a message is ready.
If the queue has at least one message in it, no signaling is done. If
the queue transitions from zero messages to N messages, the originator
will signal the recipient, via a queue-specific kqueue signal
(EVFILT_USER).
When the recipient receives the message, it will either drain the queue, or it will have some other way (e.g. socket write ready) of signalling to itself that it should write more messages from the queue into the socket.
Similar arguments apply for worker threads. While they're not writing to sockets, they can completely drain the queue every time they get a signal.
The downside of this approach is that there are 6 system calls for every packet. One to read the packet, one to signal the queue, one to receive the signal from the queue, and then the same (in reverse) to write the reply. Lowering this overhead is of high priority.
The message headers are allocated via a slab allocator, possibly a ring buffer. The message headers are fixed size.
We can't put messages into the ring buffer because of issues with TCP. We want to be able to read lots of TCP data into a buffer, and that data may encompass multiple RADIUS packets.
The message API allows for the allocation of a message, possibly with bulk data. This allocation just grabs the next free header. The bulk data allocation is discussed below.
Once a message has been created and filled out, it is written to the queue (i.e. a pointer to the message header). When the destination is finished with the message, it asynchronously notifies the originator by marking the message as handled. The originator is then responsible for updating the slab / ring allocator with the information that the message is freed.
This method ensures that there is only a single owner of a message at a time, and that the originator is the system which does all of the work for managing memory, lists, etc.
The messages consist of (usually)
When the receiver is done with the message, it marks it as "handled", and lets the originator do asynchronous cleanups.
If the receiver has to sit on the data for a long time
(e.g. cleanup_delay), it has to copy the message and any associated
packet data into a separate buffer. This copy ensures that the
message headers and packet data ring buffer contain information for as
short a period of time as possible.
The packet data ring buffer is a way to avoid memory copies, and a way to deal with variable-sized packets.
The ring buffer starts off at some size (.e.g. 64K), and tries to read the maximum sized packet into it. It generally receives a smaller packet (e.g. 200 bytes), in which case the "start" pointer can be incremented, and the next packet read into the ring.
Since the "create message" API is used only by one caller (e.g. network thread or worker thread), there is no issue with overlapping / simultaneous calls to allocate messages.
Ring buffers / message APIs are tied to a socket (for network threads), or to a source+socket (worker threads). i.e. a worker has one outbound message set per network destination. A network destination only has one outbound message set, over all workers.
There is no perfect solution here. The messages are intended to be
short-lived, but may be long-lived for things like cleanup_delay.
Messages to worker threads are short-lived, hence only one outgoing
message set.
If the message set is full, it is doubled in size (up to a limit), which gives room for more messages.
The memory and structures are owned by the originator, and only cleaned up by the originator. The recipient of the messages accesses the data, but doesn't write to it. i.e. it only writes to the message header as an async signal saying "done with this message".
In order to prevent cache line thrashing, the originator only checks for "done" messages when (1) too many messages are outstanding, or (2) when the ring buffer / message array is full.
When those limits are set, the message API tries to clean up old messages. If it's successful, allocation proceeds with the current ring buffer / message array. Otherwise, a new message array and/or ring buffer is allocated, at double the size of the old one.
Message arrays (MA) and ring buffers (RB) are tracked in a fixed-size array (not linked list). An array size of 20 should be enough for 20 doublings... at which point the system is likely out of memory.
For consolidation, if we have more than two (2) array MA/RB entries available, and the first N are free, we free the smallest ones, and coalesce the array entries so that we have the smallest number of MA/RB entries, each of which is as large as possible.
If the network thread needs to perform de-dup, cleanup_delay, or
other "wait on socket", it just leaves the reply packets in the
messages. The worker thread will then allocate larger buffers if
necessary, or just start tossing replies.
If the network thread can't write to TCP socket, it also removes the socket from the "read" portion of the event loop. This change ensures that the server isn't reading packets faster than the other end can receive replies. We then rely on TCP for flow control back to the sender. When the socket becomes ready for writing, it is also added back to the "read" portion of the event loop.
TCP sockets will need to track ongoing packets, so that they can be messaged "stop" when the TCP socket goes away. UDP sockets need this for authentication packets, but also for accounting, with conflicting packets. i.e. "you can keep processing the old packet, but don't bother sending the reply, as the client will not accept it"
When the UDP sockets do accounting tracking, they just track the minimum information necessary to detect duplicates. When a reply comes from a conflicting packet, the network thread can quench the reply by noticing it's for an old packet, and not for the new one (???) Or, the network thread has to track the old packet (??) and send an sync signal to the worker that the request is dead, and the worker should stop processing it.
When UDP sockets do dedup / cleanup_delay detection, they track the
minimum information necessary to detect duplicates, along with a
pointer to the message for the reply. If a new packet comes in, the
old message is marked "done". If a dup comes in, the same reply is
sent.
For outgoing packets, if the server is lightly loaded, caching packets
for ~5s isn't an issue. And uses less memory than what we use now,
where we cache all of the incoming packet, REQUEST, and outgoing
packet.
If the server is heavily loaded, then in the general case, new packets coming in will clear the outgoing packets. When outgoing packets aren't cleared, we can just take the 1/1000 one, copy it to a local buffer, and then clear the incoming message.
This tracking could be done by delays (i.e. if packets sit in the outoging buffer for "too long"), tho it's hard to tell what "too long" means. Instead, it should be self-clocked. i.e. if 99% of outgoing packets have been cleaned up, we should probably take the 1%, and "localize" them.
The APIs here are documented in reverse order.
The ring buffers are only used by the message layer, and aren't directly accessible by the message originator.
Each message API has one ring buffer associated with it, as above.
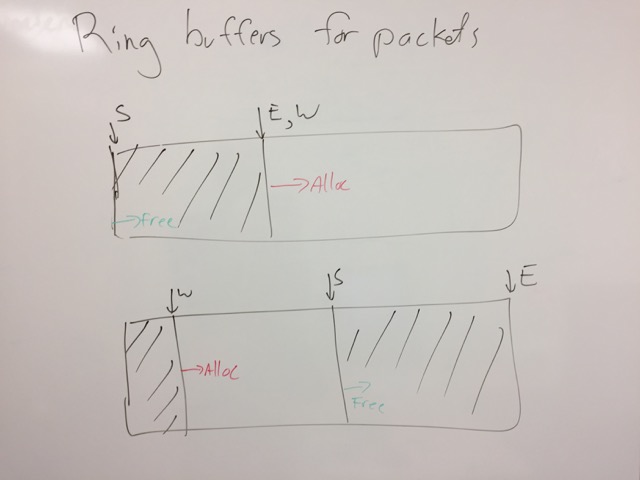
The buffer has a fixed size. The reader offset is where messages
are read from. The writer offset is where messages are written to.
When a message is freed, the reader pointer is incremented. If
reader == writer, then the ring buffer is empty, and both are reset
to zero.
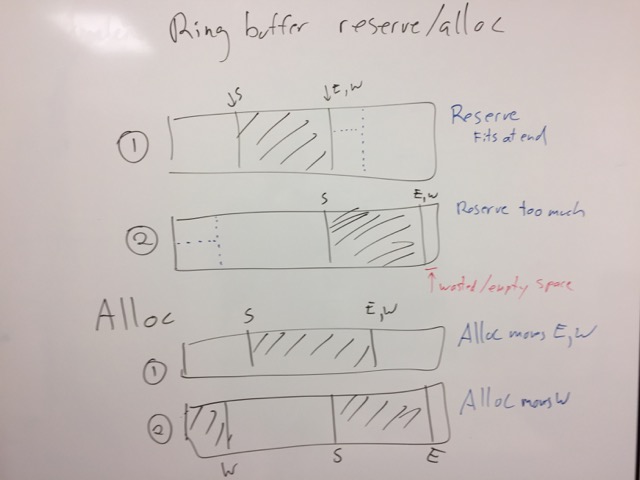
If the writer gets too close to the end (i.e. writer + max >= size),
then writer is reset to zero.
If reader > write && (writer + max >= reader), then there isn't
enough room to allocate a maximum sized packet in the ring buffer. A
new ring buffer is allocated, twice the size of the current one. It
is made as the default ring buffer for the messages.
The old ring buffer is kept around until reader == writer, and then
it is discarded.
The message API keeps track of the current and old ring buffers.
Data is read into the buffer via an underlying IO implementation. Then, packets are decoded from the ring buffwr.
Packet allocations from the ring buffer are rounded up to the nearest cache line size (64 bytes). This prevents false sharing.
Note that the read / write is done on raw sizes (e.g. 11 bytes). If the caller needs cache line alignment, it does so itself. This is because the ring buffer is for both UDP (where each packet is individual), and for TCP (packets are streamed together).
We don't use recvmmsg(), because it's broken. The timeout is
checked only after a packet is received. So if you ask for N packets,
and it receives M<N packets... it never returns (even if the timeout
hits), until the next packet is received. Maybe MSG_WAITFORONE is
better? If that's true, then we don't want a ring buffer, as it's
possible to receive multiple messages.
Note that the ring buffer doesn't keep track of where the packet start / end is. It trusts the caller to track that information.
Similarly, the ring buffer API doesn't track previous / next ring buffers, it relies on the caller to do that.
The message API is about allocating a message, and filling it out.
The Queue API is about inserting / removing elements from a FIFO
queue. The insert function returns a special flag if the queue was
empty, so that the originator can poke the receiver that another message is ready?
Or, the even loop / FD has to be exposed to the queue API, so that the queue code can do this signalling itself.
Sponsored by Network RADIUS ![]()