not logged in | [Login]
This document describes the history of the server, and the rationale behind the design decisions in version 4.
| Feature | Needed for release | Complete | Comments |
|---|---|---|---|
| Inline documentation | Yes | No | Marking up existing FreeRADIUS configs with asciidoc syntax and setting up renderer |
| Migration guides | Yes | No | Some already exist like proxy migration |
| Protocol dictionaries | Yes | Yes | |
| Multiple network threads | No | No | |
| Radmin/stats | Yes | In progress | Widely used feature |
| Sync/Async shim | Yes | In progress | Allows async code to be called synchronously |
| Async xlat conversions | Yes | In progress | Changes behaviour of xlats/escaping so should be there before release |
| Async unlang keyword - update | Yes | Yes | |
| Async unlang keyword - switch | No | No | |
| Async unlang keyword - foreach | No | No | |
| Async unlang keyword - map | No | No | |
| Async conditions | No | No | Supported by shim |
| xlat function calling convention | Yes | No | %{xlat(arg0, arg2)} - Major behaviour change - required for some async xlats to be functional |
| rlm_cache - async | No | No | |
| rlm_couchbase - async | No | No | |
| rlm_detail - async | No | No | We will likely need to print to a memory buffer, and then call write() all in one shot. It's almost impossible to have async file IO operations. |
| rlm_krb5 - async | No | No | |
| rlm_ldap - async | No | No | |
| rlm_linelog - async | No | Yes | |
| rlm_lua - async | No | No | |
| rlm_mruby - async | No | No | |
| rlm_opendirectory - async | No | No | |
| rlm_pam - async | No | Yes | PAM doesn't provide an async API. This will need to be noted in the documentation. |
| rlm_passwd - async | No | Yes | The module just looks up hashes in memory. It's already async. |
| rlm_perl - async | No | No | |
| rlm_python - async | No | No | |
| rlm_redis - async | No | No | |
| rlm_redis_ippool - async | No | No | |
| rlm_rediswho - async | No | No | |
| rlm_rest - async | No | Yes | |
| rlm_securid - async | No | Yes | RSA does not provide an async API. This will need to be noted in the documentation. |
| rlm_sigtran - async | No | No | |
| rlm_sql - async | No | No | |
| rlm_sqlcounter - async | No | No | |
| rlm_sqlippool - async | No | No | |
| rlm_unbound - async | No | No | |
| rlm_winbind - async | No | No | |
| rlm_yubikey - async | No | No |
The core of the server has grown in complexity over time. There have been efforts to clean it up and rearchitect it, with some success. For example, version 3.0.0 was smaller than the version 2.2.x server it replaced, while having more functionality. At the time of writing (September 2016), version 3 is now substantially more complex than version 2.
We would like to simplify the design of the server, and simplify the
code. As a case in point, listen.c is terrible. It is complex, and
has many special cases in the general code path. The process.c file
is a bit better, and the RADIUS state machines are clearer. But
everything in process.c is special-cased, and (for example) the
"originate CoA" functionality is clearly a hack.
On top of that, we would like to move all of the RADIUS knowledge outside of the server core. The rationale for this is as follows:
Hard-coding a protocol into the server core makes it easy to write hacks such as "originate CoA".
we would like to add more protocols (e.g. DHCP and DHCPv6) to the server core. Right now, the DHCP processing is done as if the packets were RADIUS.. which is not good.
We would like to increase the performance of the server, and remove all internal locks / mutexes, issues that degrade performance. We would like the server to scale to tens of thousands of input network connections, which is currently impossible.
The solution is a radical redesign of the server core. All protocols are moved out of the server core and into plugins. The core becomes a configuration file loader, thread manager, and policy language interpreter. Nothing more.
Data is read from the IO layer.
Data is turned into packets in the Transport layer.
Packets are processed by the Application Layer.
Processing is done by Threads, both worker threads (policies) and network threads (read/write).
Threads exchange information via Messages.
The unlang interpreter has had a few major rewrites over the years. It was originally written as a recursive interpretor for modules, and not much else. Version 2 added statements such as "if", "else", "switch", etc. Which was a bit of a miracle given the state of the code.
We started re-working the code in the v3.1.x branch, and then discovered that even more major rework was necessary. This led to the v4.0.x branch.
The unlang interpreter in v4.0.x is iterative instead of recursive (so we don't blow up the C stack).
Each REQUEST has a stack associated with it. That stack is used to
push recursive unlang calls ("if" statements, blocks, modules, etc.).
The interpreter is entirely iterative, where it loads a stack frame,
and calls a type-specific interpreter. The type-specific interpreter
can in turn push items onto the stack, for the main routine to
discover.
This design means that each REQUEST is effectively its own thread.
Which means that we can suspend or resume the REQUEST processing
without affecting the main C thread, and it's stack.
There have been a few attempts over the years to redesign the code, starting "top down". These attempts failed, as they became too complex. This attempt (bottom up) at fixing the interpreter first has allowed us to make good progress in a short period of time.
A test implementation of yield / resume in the v4.0.x branch works today. This development led to the next stage in the design.
Threading has always been a problematic issue in the server. Each request coming in is assigned to a random thread. When a packet is proxied, the response may come back to a different thread than the one which sent the proxied packet. These issues mean that we either need a lot of locks (which are slow) to manage threading issues, or we try to avoid locks, which is faster but unsafe.
The changes to the unlang interpreter motivated related changes to the
threading model. As each REQUEST can be suspended and resumed, it
is now possible for a worker thread to manage multiple REQUESTs
itself.
In the case of proxying, the thread can now send the proxied packet,
and yield on the current REQUEST. When the reply comes in, the
reply is associated with the REQUEST, and the REQUEST is resumed.
A side effect is that the "originate CoA" functionality now becomes trivial. The worker thread runs a module which originates a CoA packet, instead of proxying the current packet. Or, if the administrator desires to proxy the packet to two destinations, he just lists the "proxy" module twice in series.
This design also means that all of the special-purpose logic around proxying goes away, and just becomes normal module fail-over, load-balancing, etc. As those code paths are well tested, we know that they work. Also, removing duplicate / special-purpose code is a Good Thing.
The only caveat with the above is that the outgoing sockets (proxy, SQL, LDAP, etc.) are now thread-specific. This limitation is fine for systems such as RADIUS proxying and LDAP, in which a connection can have multiple "in progress" requests and responses. It is less fine for some SQL (e.g. Postgresql), where each connection can only handle sequential requests / responses.
This limitation can also be a problem for RADIUS proxying, where the server is now using many outgoing TCP / TLS connections, instead of one. That problem can be mitigated by having a local proxy thread for the outgoing packets. The local proxy thread can accept packets from the worker threads, send them to the home server, and push the replies from the home server to the appropriate worker thread.
Another caveat is that the proxy.conf file goes away. The
configuration for each home server is now in a separate module (I
think, so far...), and the home server pool fail-over, load-balance,
etc. becomes normal module fail-over and load-balance.
As with the changes from version 1 to version 2, this change means that simple proxy configurations become more complex. This is the price to pay for complex proxy configurations becoming simple, where they were previously impossible.
In the current model, we have a distinction between network threads;
which read/write packets to the network, and worker threads; which run
a REQUEST through a virtual server. The distinction is likely
necessary for a few reasons.
When we have UDP sockets, worker threads can write their replies to the UDP socket without any inter-thread communication. When we have TCP sockets, this is not possible. Each worker thread has to enqueue its packets into the TCP stream, to be sure that the data is not sent inter-leaved.
In fact, similar restrictions apply to UDP. UDP send buffers can get
full, and the OS can return EAGAIN on non-blocking sockets, or
EWOULDBLOCK on blocking sockets. Until now, we have ignored these
issues, and gotten away with it, largely because the server cannot
fill a 1G pipe with RADIUS traffic. The hope is that version 4 can
achieve this higher performance, in which case it would run into these
issues with UDP sockets.
The current system of HUPing the server does not work well. In some cases it can cause the server to crash, and in others leak memory.
With a distinction between I/O threads and worker threads, there's is a natural cleavage in process space. I/O threads would exist only in the frontend process, worker threads in the backend. This would allow the backend process to be restarted whilst maintaining connection state.
Experience with OpenSSL has also shown that there's a significant performance
bottleneck imposed by internal mutexes. These mutexes are used to protect
reference counters for various OpenSSL structures. In order to solve the
problem of mutex contention, we need to ensure each SSL * and
SSL_CTX * is only used by a single thread. This would allow us to disable all
OpenSSL mutexes, removing the bottleneck.
Pinning multiple related requests in the frontend, to a single worker in the backend would allow us to achieve the above.
We would also like to be able to separate the network protocols
(UDP, TCP, TLS, "detail" files) from the application state machines
(Access-Request, Accounting-Request, etc.). The current design has
the state machines all in process.c, and the network protocols in
listen.c. This design worked to hack things together, but it has
become unsustainable and unmaintainable moving forward.
After a few abortive approaches, the decision was to just start
writing a new Access-Request state machine that used the yield /
resume functionality of the new interpretor, while still using the old
UDP listeners. The goal of this approach was to see what was possible
by hacking something together, without breaking any existing
functionality.
The outcome was (as of September 2016) src/modules/proto_radius/,
with sub-files proto_radius_auth.c, proto_radius_acct.c,
proto_radius_coa.c, and proto_radius_status.c. A cursory
examination of those files shows that they are extremely short, and
the main flow is "top to bottom", with a few caveats for yield /
resume. These files are significantly simpler than their equivalents
in process.c and auth.c, while having the same functionality.
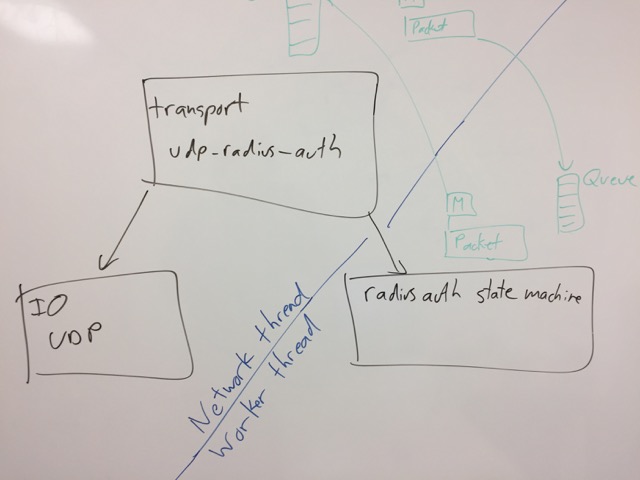
At the time of writing those modules, the design of the IO layer was still undetermined. Once the modules were written and integrated into the existing code, the next step became simpler. We would divide the code into three logical pieces:
io - abstracts the network protocol (TCP, UDP, etc), by exposing an API to connect / accept / read / write / close different protocols.
application - abstracts the application layer (Access-Request processing, etc.). The API here is largely parse / process.
transport - glues the previous layers together. This layer is responsible for IO related issues which are application-specific. e.g. de-dup of RADIUS requests for UDP, but not TCP.
The IO layer is responsible for abstracting the network protocols. It exposes an API which has connect / accept / read / write / open / close / print / parse / debug , etc. for different protocols. Examples are TCP, UDP, TLS, files, unix sockets, etc.
TLS is a bit of a special case, because it sends its data over TCP / UDP. But the general approach here is sound.
The IO layer does not know about applications that use it, which enables the implementations to be re-used across multiple applications. It also means that the applications don't know about the IO methods (mostly), so that RADIUS over TCP becomes about as easy to write as RADIUS over UDP.
The application layer is responsbile for implementing the application layer processing. The worker threads spend the bulk of their time executing the state machines provided by the application layer. The API here is largely compile / debug / parse / process.
Crucially, the application layer is IO-independent. It knows nothing about any IO method. It instead is called by the transport layer when packets are received, and it in turn sends the replies back to the transport layer.
For various reasons, this layer also provides an asynchronous signal
API. This API is intended to send signals to the application layer
about a particular request. As the network thread is different from
the worker thread, it cannot access a REQUEST directly. Instead,
the network thread must send a signal to the worker thread which
requests that a particular action is taken on its behalf.
e.g. for RADIUS Access-Request packets, a DUP signal. The DUP signal
can be sent at any time in the REQUEST processing, including at a
time when the worker thread thinks it is done, and would like to clean
up / destroy the REQUEST. The worker thread can then be free to do
what it wishes with the REQUEST, secure in the knowledge that no
other code in the server will be touching that REQUEST.
The transport layer is responsbile for gluing together the IO layer and the application layer. It provides APIs which are largely identical to the io layer. The crucial difference is that it is application aware.
For example, TCP sockets do not require de-dup of Access-Request packets, but UDP sockets do require such de-dup. In contrast, de-dup is not necessary for Accounting-Request packets for either TCP or UDP. However, if a TCP socket is unexpectedly closed, the transport layer should signal Access-Request packets to stop processing. The transport layer should probably allow Accounting-Request packets to continue being processed. The theory is that it is always useful to record accounting data, even if the NAS doesn't know you're doing this.
In the current design of the server, there is little distinction between the network protocols. All protocols are (largely) treated identically, and all protocols are strongly tied to applications.
Fixing that design means that the protocols and applications are loosely coupled. Which means that for example, a "detail" file reader just becomes a "files + Accounting-Request" implementation. It also becomes easy to update the detail file to read CoA packets. That's just a "files + CoA-Request" implementation. Even though this would still be new code, the new code would be small and simple.
Where network protocols need to handle multiple applications (e.g. Access-Request and Status-Server), that knowledge is in the transport layer, and not in the application layer.
In current versions of the server, the processing sections are
authorize, authenticate, etc. The names are largely "ad hoc". and
don't show any consistency. Even worse, the processing of
Access-Challenge and Access-Reject packets is, at best, a hack. They
are processing in the post-auth section, as a separate
Post-Auth-Type.
The processing sections for DHCP are a bit better named, but are still "surprising". The design for version 4 has to do better.
The solution is to note that the server is sending and receiving packets, and the packets have names. The simple solution is to then name the sections for what they do, and what they process.
For example, recv Access-Request is clearer than authorize. and
send Access-Challenge is clearer than post-auth {
... Post-Auth-Type Challenge { ... } }. There is some magic for the
authenticate section, and the use of Auth-Type, but idea is sound.
Similar rules apply for DHCP, VMPS, ARP, etc. BFD is a little
different, as it has timers which fire periodically. We will have to
re-visit that at a later date. Perhaps via a timer subsection?
There is some additional magic for the do_not_reply policies. That
is, if the server is not replying, it could still arguable process a
send nothing section. The exact functionality here is to be
determined.
The source code needs to be reorganized. The following is a suggestion:
src/ source code
io/ # low level network IO
tcp.c
udp.c
unix.c
tls.c
files.c
radius/
server/
auth.c
acct.c
status.c
coa.c
tcp_io.c
udp_io.c
tls_io.c
files_io.c
client/
auth.c
acct.c
status.c
coa.c
tcp_io.c
udp_io.c
tls_io.c
files_io.c
modules/
rlm_*
main/
...That way when a new application is added to the server, it can go into it's own directory.
The individual directories can have filenames which appear in other directories. Stupid debuggers will get confused. Reasonable ones will not get confused.
Right now, all of the module configuration is in the
raddb/mods-available directory. This ends up confusing people who
install a package, and get configuration files for modules which they
don't have.
The solution is to put the module configuration into the same
directory as the module source, perhaps in a conf subdirectory. The
build system can automatically determine which file goes where. The
main conf or raddb directory is thus empty, and people only ever
see configurations for modules which they have installed.
xlat needs to be updated to integrate with the unlang interpreter, and to be async.
paircompare should probably go away.
Templates and maps need to be async. All callers of them need to be updated to be async. See paircompare for suggestions on how this can be done.
sql needs to be async.
"Read clients" needs to be moved from sql, and into a clients virtual server.
clients need to be in a virtual server. The dynamic_clients needs to be renamed to clients. The clients.conf file needs to in an rlm_client module.
The tls needs to be it's own virtual server.
Sponsored by Network RADIUS ![]()